redraft
ossReactive LLM inference. When you edit an LLM's context, redraft recomputes only what the edit actually changed on both sides of the call: the prompt (reused KV prefix) and the answer (salvaged via self-speculative replay), implemented as a streaming mode inside llama.cpp.
Interactive LLM applications keep re-invoking the model over contexts that barely change: a user fixes a typo in a document and the summary regenerates, an agent updates one line of a plan and the review regenerates. The prompt side of this waste is a solved problem, since prefix caching reuses the unedited prompt prefix. The output side isn’t: whatever fraction of the previous answer would survive the edit verbatim is thrown away and re-decoded serially, token by token, at full price. redraft treats inference as an incremental computation, recomputing only what an edit actually changed on both sides of the call.
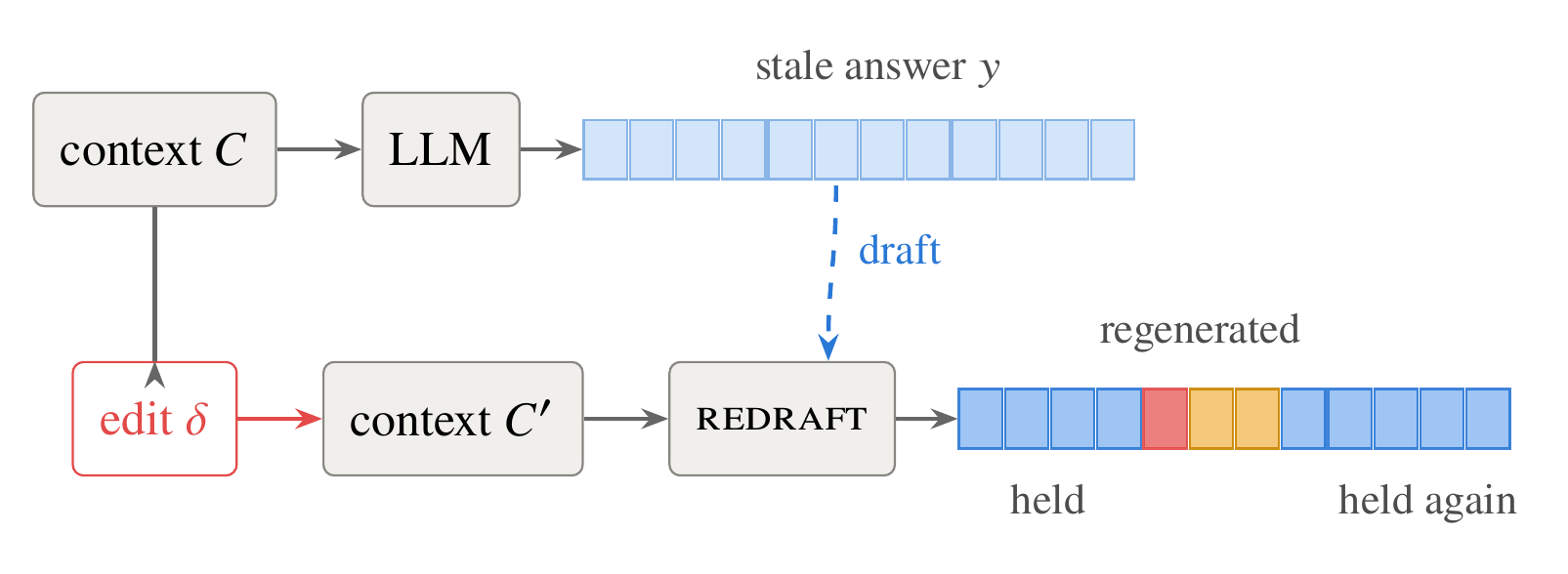
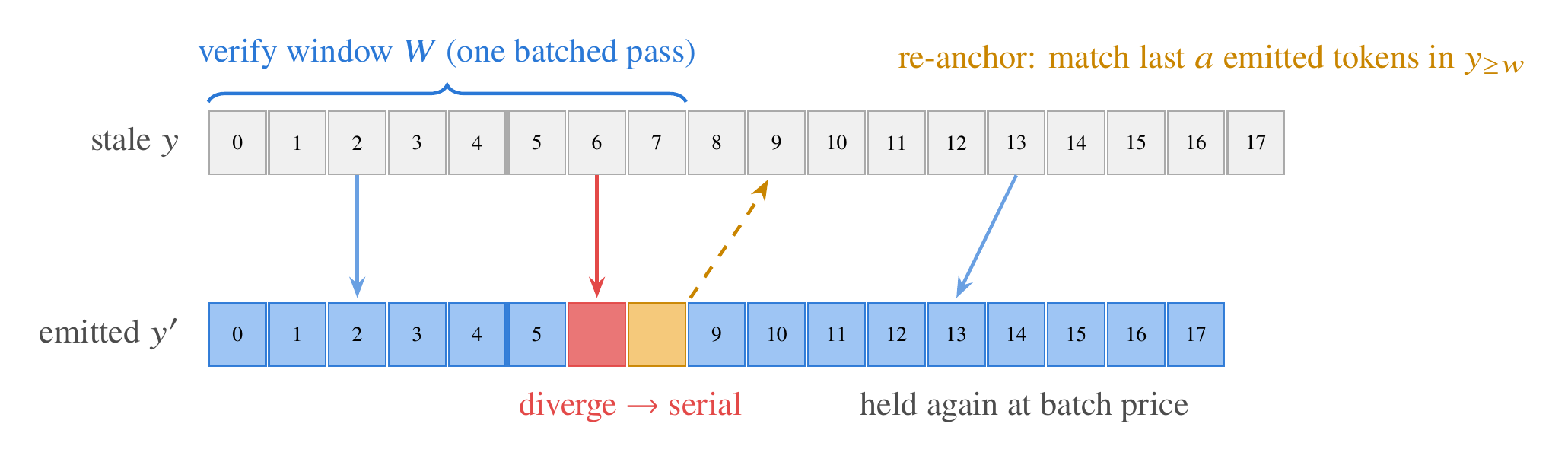
The mechanism: the stale answer is replayed as a self-speculative draft under the edited context, verified in batched windows, and re-anchored after each divergence. Spans the model still agrees with are held at batched-verification price; where it diverges, a short serial burst decodes the correction and the draft re-anchors further down the old answer, so agreement past the divergence is salvaged too, not just the common prefix.
Why the obvious metric lies
Teacher-forcing the stale answer under the new context reports 85–98% agreement even when free decoding would flip the answer, an exposure-bias artifact. Measured on free decodes instead, reuse ceilings are low because greedy decoding is chaotic in the context: an edit that changes nothing semantically still reshuffles about half the output tokens. Exact greedy equality, the lossless contract of standard speculative decoding, inherits all of that chaos and collapses held fractions to the naive ceiling.
redraft instead accepts a draft token when its logprob sits within a tolerance band of the argmax, with the band scaled by the local top-k entropy so it transfers across models. An 18-rule sweep found this entropy-scaled rule the only family with zero correctness regressions across 3B, 14B, and 35B models while holding the most tokens (median 68%). Fixed-tolerance rules do not transfer across models: the calibration has to be per-distribution, not a global constant.
Numbers
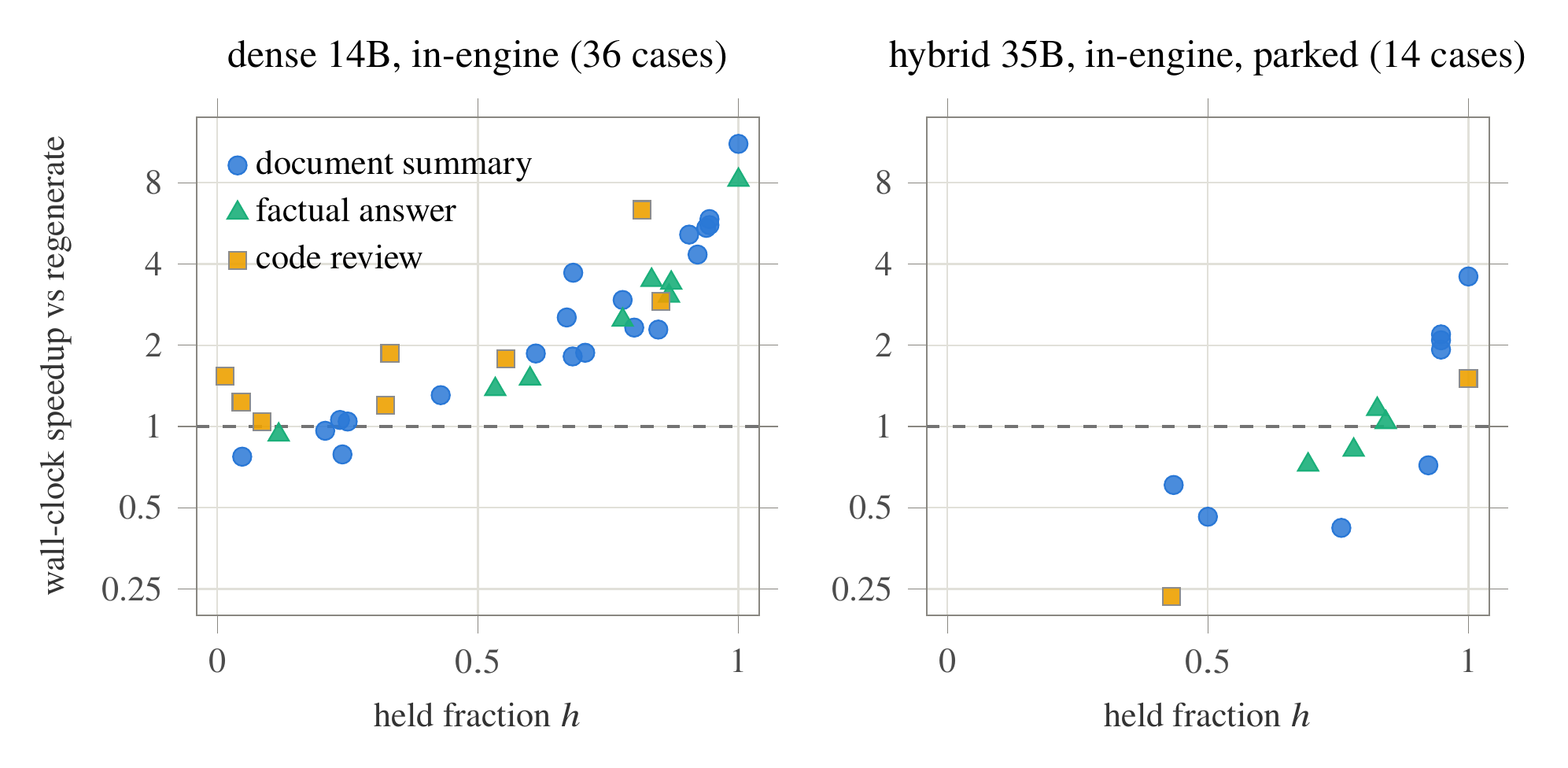
Headline results, Qwen2.5-14B, 36-case edit suite, wall-clock vs. full regeneration:
- Document summaries: 2.31× median
- Factual answers: 2.76× median
- Code review: 1.66× median
- Up to 11.1× on cosmetic edits whose answer is fully held
Placement decides the economics: a client-side implementation of the identical algorithm sits at parity or loses to serving overhead; moved inside the engine, every category wins. On a hybrid Gated DeltaNet 35B, where speculative rollback is impossible because partial KV rewind isn’t supported, a reprocess-on-divergence verifier with a parked post-template state gets long, mostly-stable answers to 1.9-3.6×.
Layout
paper/: preprint with method, acceptance-rule math, cost model, all results.experiments/m0-acceptance/: the measurement harness and research trail (milestones m0-m9), covering the stabilize loop and acceptance rules (m0/), llama.cpp server patches and the C++ stabilizer core (engine/), and the annotated 36-case edit suite with six fact-flip canaries (cases/).space/: interactive demo, a reactive document editor racing redraft against regeneration over a FastAPI app in front of the patched server.
History
The idea started as the incr question (track dependencies, recompute only the delta) applied end to end to inference. Milestone zero found the obvious metric invalid, since teacher-forcing the stale answer masks real divergence; the honest free-decode ceiling turned out low and edit-independent, which pointed at output stabilization as the actual primitive. The milestone trail includes the negatives that redirected it: client-side placement loses, fixed tolerance bands don’t transfer across models, recurrent memory silently corrupts under dense rollback.
License: Apache-2.0.